Product
Verified sovereign AI runtime
Run inference, deploy agents, and build knowledge bases with receipt-backed execution, jurisdiction controls, and provenance-aware audit trails.
Platform
Runtime capabilities for first pilots
Sovereign inference
OpenAI-compatible chat, embeddings, images, and audio with receipt-backed execution and jurisdiction controls.
Agent hosting
Deploy long-running AI agents on sovereign nodes. Built-in inference, knowledge base access, persistent memory, hourly billing.
Knowledge bases & RAG
Upload documents. Embed with pgvector. Query by meaning. Attach to chat and agents with source-aware provenance.
MCP server
One endpoint for Claude Code, CrewAI, LangGraph, or any MCP client. Knowledge search, KB chat, memory, and agent deployment tools — no SDK required.
Guardrails & compliance
PII detection, prompt injection defense, content safety filters, and audit export for compliance reviews.
Jurisdiction controls
Pin workloads to approved countries or regions with verified node location signals and policy-aware scheduling.
Agent memory
Persistent key-value memories and compressed session diaries. Agents retain context across conversations and restarts.
Signed receipts
Ed25519 signature on the core execution envelope, with attached metadata for model, jurisdiction, and provenance.
Full visibility
Dashboard with spending, job history, audit trail, and node assignments. Scoped API keys with granular permissions.
Architecture
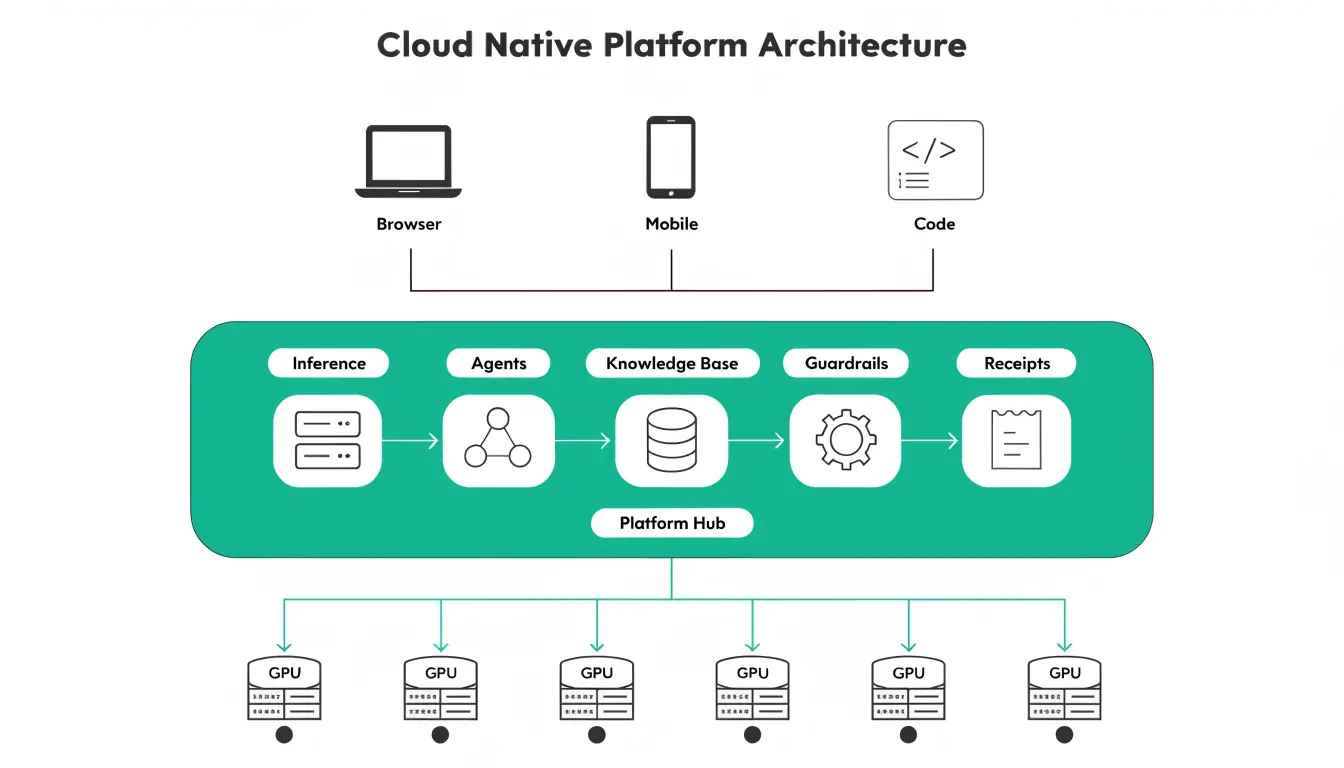
Platform overview
Clients connect through the hub orchestrator. The hub schedules workloads across verified compute nodes. Each layer — inference, agents, knowledge bases, guardrails, receipts — is exposed as one managed runtime with policy-aware routing and auditable outputs.
Verification
How receipts work
When a node completes a job, it produces an Ed25519 signature over the current RYV1 core fields: job ID, node public key, result hash, and metering units. Model, jurisdiction, timestamps, and retrieved chunks can be attached as audit metadata and reviewed separately.
Custom models & fine-tuning
Upload a GGUF model or fine-tune an existing one with QLoRA. Same API, same receipts, same sovereign routing. Your model runs on real GPU hardware and you pay per job.